7 zagadnień skalowania aplikacji,
które musisz znać jako Software Developer29.07.2024
Czym jest skalowalność aplikacji?
Skalowalność aplikacji to zdolność systemu lub aplikacji do efektywnego radzenia sobie ze wzrostem obciążenia. Wyobraź sobie, że jako software developer tworzysz stronę internetową, na której użytkownicy mogą dzielić się ze sobą zdjęciami swoich kotów 😻
Na początku odwiedza ją tylko kilka osób dziennie, więc działa płynnie i szybko. Jednak co się stanie, jeśli nagle znany w sieci influencer opublikuje na Twojej platformie viralowe zdjęcie swojego kota? Jeszcze tego samego dnia tysiące osób zacznie odwiedzać aplikację, aby założyć na niej swoje konto, zobaczyć kociego celebrytę i pochwalić się znajomym zdjęciem swojego pupila. Skalowalność to właśnie umiejętność dostosowania się systemu do takiego wzrostu ruchu bez pogorszenia wydajności i płynności.
Skalowalność jest kluczową cechą dojrzałych systemów IT, ponieważ pozwala aplikacjom dynamicznie rosnąć w czasie i obsługiwać więcej użytkowników oraz danych, zachowując przy tym dobrą wydajność. Jako software developer, zrozumienie skalowalności pomoże Ci tworzyć systemy i usługi, które są stabilne i gotowe na rozwój.
1. Skalowanie Horyzontalne i Load Balancing
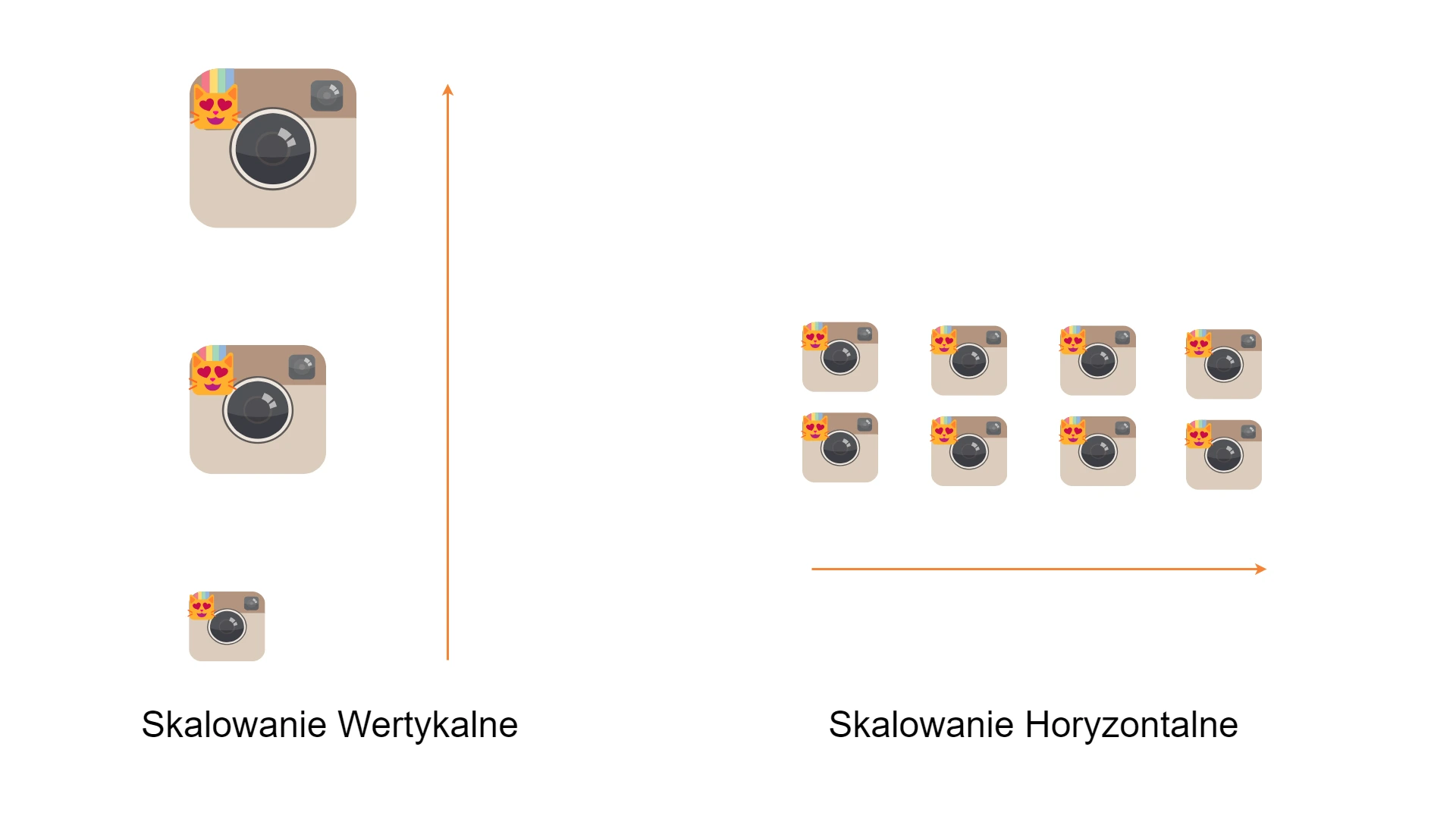
Skalowanie horyzontalne (horizontal scaling) zwane także skalowaniem poziomym, polega na zwiększeniu liczby serwerów systemu, aby następnie podzielić między nie całkowite obciążenie systemu.
Skalowanie wertykalne i horyzontalne
Skalowanie horyzontalne jest z reguły dużo lepszym rozwiązaniem niż skalowanie wertykalne (vertical scaling), które polega na zwiększaniu mocy obliczeniowej jednego serwera. Skalowanie pionowe jest dużo droższe i ograniczone w przeciwieństwie do skalowania poziomego, w którym możesz dodawać wiele mniejszych instancji, które będą wspólnie obsługiwać rosnący ruch. Każdy nowy serwer będzie zajmował się częścią użytkowników i danych, co zmniejszy obciążenie na poszczególnych maszynach i poprawia ogólną wydajność aplikacji. Podejście to połączone z wdrożeniem aplikacji w chmurze umożliwia niemal nieskończone skalowanie zasobów.
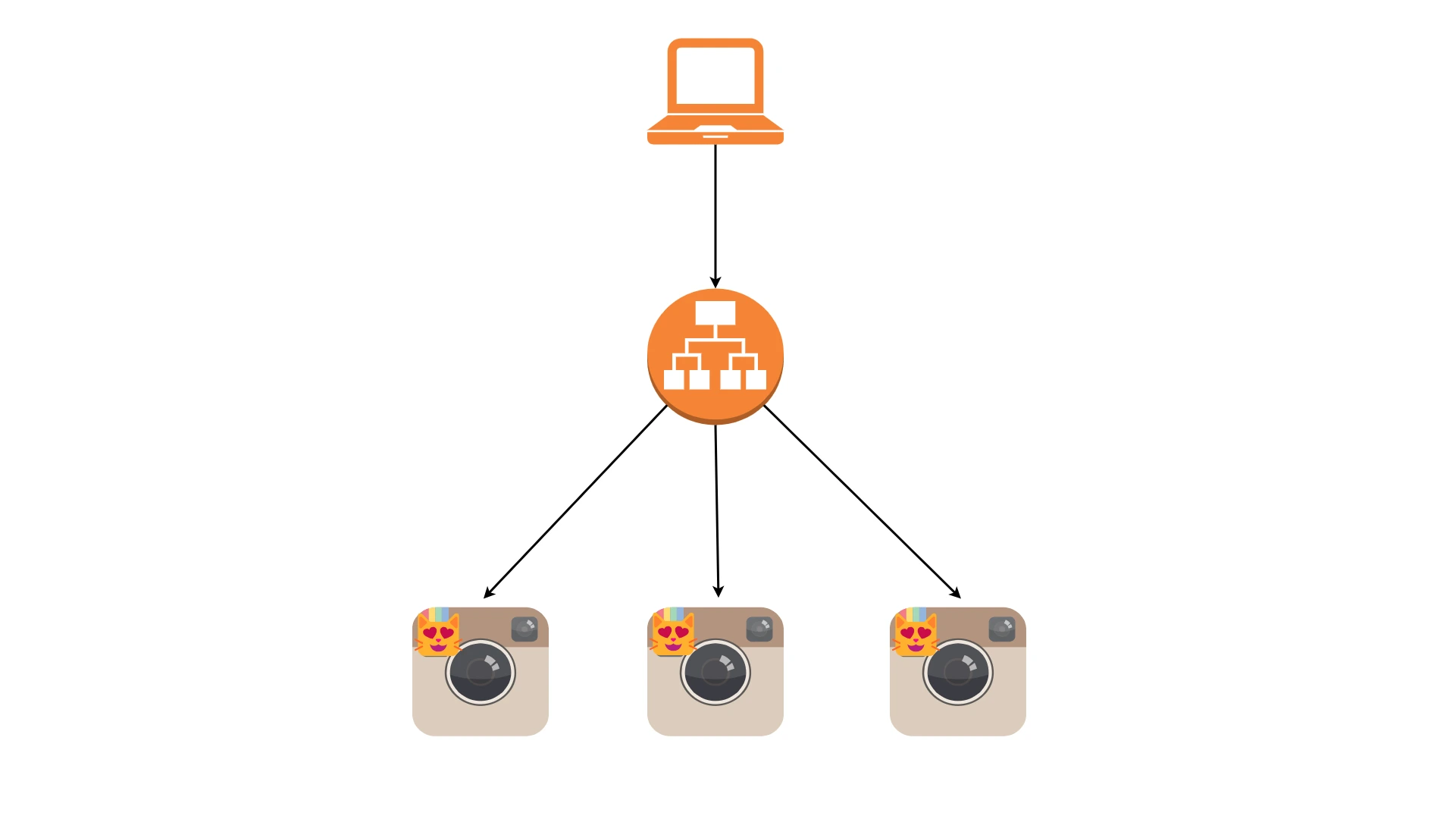
Load balancing
Load balancing to technika zarządzania ruchem sieciowym, która ma na celu (najczęściej) równomierne rozłożenie obciążenia (czyli ruchu sieciowego) na wiele serwerów. Jest to jeden z kluczowych elementów, który umożliwi Ci w ogóle wykorzystanie faktu skalowania horyzontalnego. Dzięki loadbalancerom Twój system zyska dodatkową warstwę abstrakcji. W architekturach mikroserwisowych możesz skalować poszczególne usługi niezależnie od siebie, a one nie muszą być nawet tego świadome, ponieważ nie komunikują się ze sobą bezpośrednio, lecz poprzez loadbalancer.
Warto wspomnieć, że load balancery u dostawców chmurowych (AWS, Azure, GCP) są usługą wysoko dostępna (high available). To znaczy, że system przestanie całkowicie działać tylko wtedy, jeśli wszystkie serwery ulegną awarii, a utrata na przykład jednego z serwerów jest całkowicie bezpieczna, ponieważ ruch będzie płynnie przekierowany na inne instancje przez load balancer.
2. Bezstanowe Usługi
Bezstanowe usługi (stateless services) to taki sposób projektowania aplikacji, w którym każda interakcja (czyli każde zapytanie od klienta) jest niezależna i nie wymaga przechowywania informacji o wcześniejszych interakcjach. Oznacza to, że serwer nie musi pamiętać, co wydarzyło się wcześniej, aby poprawnie obsłużyć bieżące zapytanie.
Bezstanowość to kolejny element, który jest wymagany, aby w bezproblemowy sposób skorzystać ze skalowania horyzontalnego aplikacji. W przypadku awarii, któregokolwiek z serwerów bezstanowość umożliwia bezproblemowe przeniesienie ruchu na inny serwer, ponieważ każde z zapytań zawiera kompletną informację potrzebną do jego obsługi.
Alternatywą dla bezstanowości instancji jest posiadanie stanu i jego synchronizacja między instancjami. Nie jest to trywialny problemem do rozwiązania i wymaga sporo doświadczenia. Synchronizacja między serwerami może nierzadko stać się wąskim gardłem wydajności, z powodu wzajemnego blokowania się instancji. Powinniśmy zatem zawsze starać się, aby aplikacja zawsze trzymała stan na zewnątrz np. w bazie danych.
3. Automatyczne Skalowanie
Kolejnym zagadnieniem, które musisz znać, jest automatyczne skalowanie aplikacji. Dostawcy chmury np. AWS przygotowali w tej sprawie wiele udogodnień dla programistów. Przykładem jest automatyczne Auto Scaling Groups dla instancji EC2, skalowanie w usłudze zarządzania kontenerami ECS, czy też skalowanie w zarządzanym klastrze Kubernetes (EKS). Dzięki nim możesz osiągnąć zasoby szyte na miarę Twojego systemu. Jeśli ruch na aplikacji się zwiększa — serwery są automatycznie dodawane. Dzięki loadbalancerowi i bezstanowości aplikacji jest to całkowicie transparentne dla innych działających już wcześniej instancji. Jeśli z kolei ruch obniża się (na przykład w nocy), serwery są usuwane, co powoduje zmniejszenie kosztów, które trzeba by było ponieść na zasoby, których w danym momencie nie potrzebujemy.
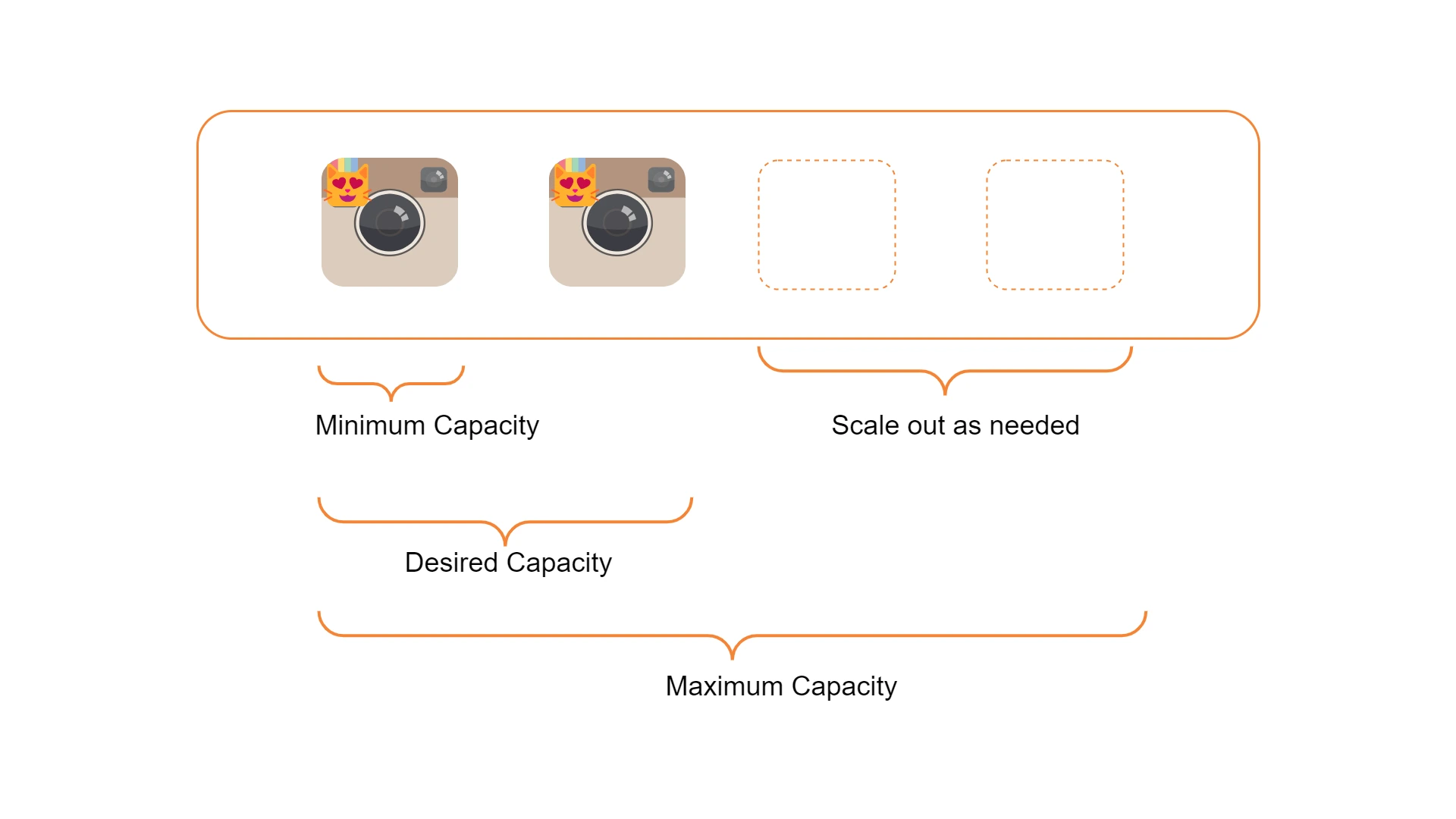
Automatyczne skalowanie
Popularnymi parametrami autoscalerów są Minimum Capacity, które określa dopuszczalną minimalną liczbę działających instancji i analogicznie Maximum Capacity określa ich maksymalną liczbę. Desired Capacity jest to parametr, który określa liczbę instancji, z którą auto scaling group’a zostanie zainicjowana i wokół którego będzie oscylował system, obsługując wydarzenia związane ze skalowaniem w dół czy w górę.
4. Caching i CDN
Caching to technika, która polega na przechowywaniu kopii danych w łatwo dostępnej pamięci podręcznej, aby przyspieszyć dostęp do tych danych. Pamięć podręczna jest zawsze szybsza niż na przykład bezpośredni odczyt z relacyjnej bazy danych. Wyobraź sobie, że wspomniany influencer wrzuca zdjęcia swojego kota do Twojej aplikacji. Tysiące użytkowników wykonuje zapytania o jego dane, aby zobaczyć wspomnianego kota. Czas odpowiedzi i ogólna wydajność systemu mogą być znacząco ulepszone poprzez załadowanie tych często wykorzystywanych danych do warstwy cache.
Warto wspomnieć, że dane w cache nie zawsze mogą być tymi najbardziej aktualnymi. Dzieje się tak w momencie, gdy jakaś wartość zmieni się w bazie danych, lecz jej odpowiednik w cache jeszcze nie zostanie zmieniony lub wyczyszczony. Dane te z racji przechowywania w pamięci podręcznej są też nietrwałe, a więc każdy najmniejszy restart urządzenia może spowodować ich utratę.
Caching jest więc doskonałym rozwiązaniem dla często używanych danych oraz tych, które rzadko się zmieniają. Cache jest to z reguły relatywnie tanie rozwiązanie do przechowywania danych, które odciąży Twoją bazę danych i umożliwia wejście Twojej aplikacji na wyższą skalę.
Content Delivery Network (CDN) jest to rozwiązanie dla aplikacji działających globalnie (w różnych krajach, czy na różnych kontynentach). Przykładami gotowych narzędzi są np. AWS CloudFront, czy Cloudflare. CDN pomoże Ci odciążyć aplikację poprzez skrócenie geograficznej drogi połączenia, dzięki czemu dane są pobierane z serwera, który jest najbliżej użytkownika. Można w bardzo dużym uproszczeniu powiedzieć, że CDN to rozproszony między różne regiony cache.
5. Komunikacja Asynchroniczna
Komunikacja asynchroniczna to sposób wymiany danych, w którym nadawca i odbiorca nie muszą być w bezpośrednim kontakcie w tym samym czasie. Dzięki temu systemy i aplikacje mogą działać bardziej wydajnie, nie blokując się nawzajem podczas przetwarzania zadań.
Wyobraź sobie, że wysyłasz wiadomość do znajomego. Zamiast czekać, aż znajomy natychmiast odpowie, możesz kontynuować swoje działania i wrócić do odpowiedzi później. Podobnie działa komunikacja asynchroniczna między serwisami.
Zadania długotrwałe lub nie wymagające natychmiastowego wykonania są dobrymi kandydatami do przetwarzania ich asynchroniczne. Będą to operacje takie jak wysyłanie emaili, generowanie raportów, przetwarzanie obrazów, czy filmów. Operacje asynchroniczne wykonasz poprzez wykorzystanie kolejek, komunikacji pub/sub, czy wielowątkowości.
6. Replikacja Bazy Danych
Replikacja bazy danych to proces kopiowania i synchronizowania danych z jednej bazy danych na inne instancje tej właśnie bazy danych. Bazę możesz replikować na dwa sposoby.
Pierwszy poprzez tworzenie zapasowej kopii bazy, na którą możesz przełączyć ruch w razie awarii (standby replica). Przykładem gotowego rozwiązanie może być na przykład AWS RDS Multi-AZ. Ten sposób replikacji nie przynosi zwiększonej wydajności, ani też nie zwiększa skali aplikacji. Jedynie co zyskasz to dużo większa dostępność systemu w razie awarii.
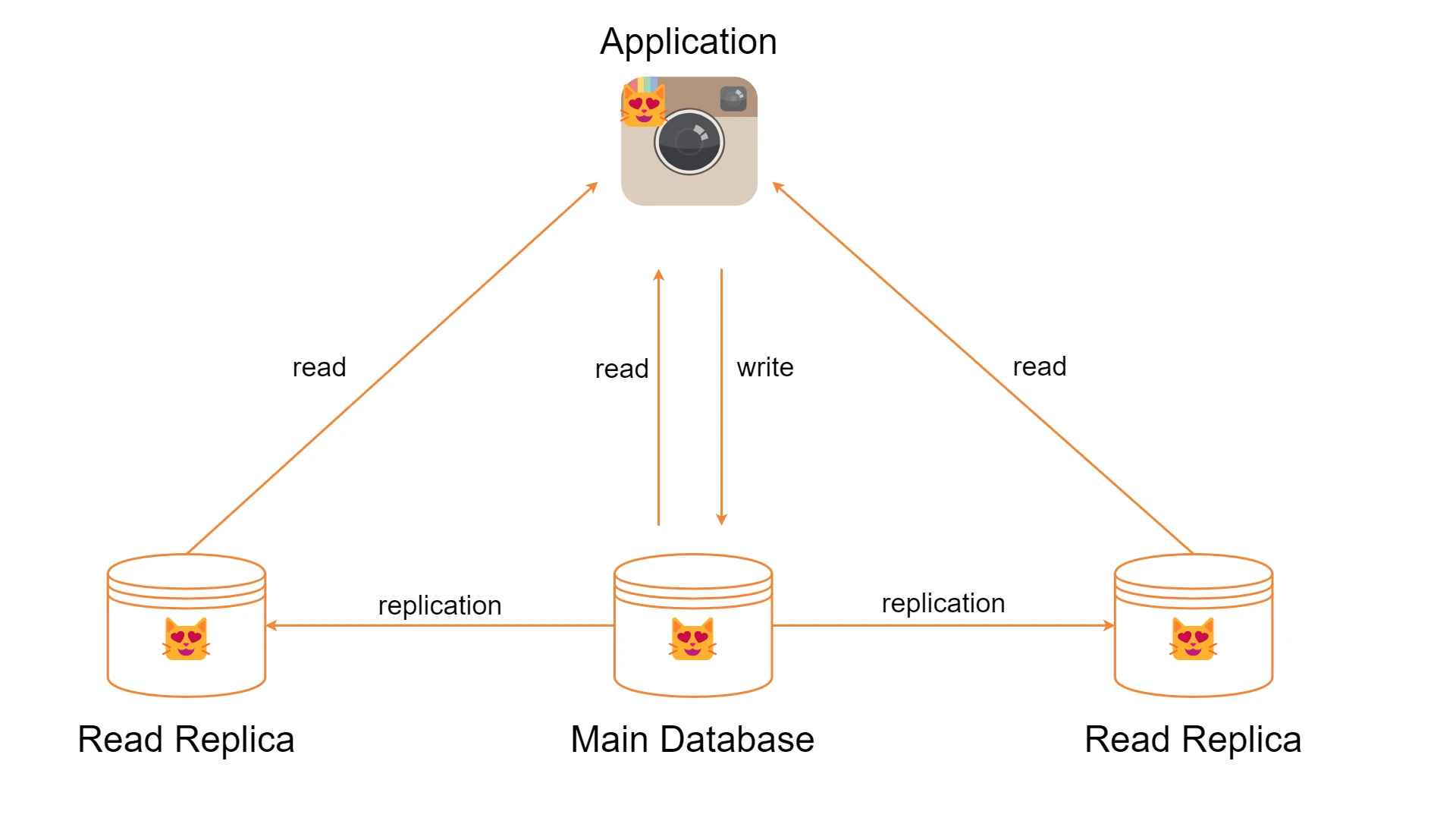
Replikacja bazy danych
Drugi sposób natomiast pomoże Ci znacznie poprawić wydajność systemów, zwłaszcza tych, które wykonują dużo odczytów (read heavy). Sposób ten polega on na stworzeniu replik tylko do odczytu (read replicas). Operacje związane z odczytem danych przekierowywane są na repliki. Główna baza staje się za to odpowiedzialna za operacje zapisu, a dzięki swoim replikom zostanie znacznie odciążona. Przykładem gotowego narzędzia chmurowego może być AWS RDS Read Replicas.
7. Testy wydajnościowe
Ostatnim w zestawieniu, lecz bardzo ważnym zagadnieniem w ogólnym procesie dążenia do skalowania aplikacji są testy wydajnościowe. Dzięki nim będziesz w stanie przeanalizować wąskie gardła systemu, które ograniczają jego skalę. Dużo mniej stresującą sytuacją jest, gdy dowiesz się, że Twoja aplikacja przestaje działać dla obciążenia 10.000 użytkowników w trakcie testów wydajnościowych, niż jeśli dowiesz się tego samego w trakcie awarii na produkcji, która to dotknęła wspomnianą liczbę klientów.
Dobrym pomysłem jest również uruchamianie tego samego zestawu testów wydajnościowych co pewien czas. Takie podejście pozwali Ci w sposób ciągły monitorować zwiększenie lub obniżenie wydajności systemu i powiązać je z konkretnymi zmianami w kodzie.
Podsumowanie
Skalowanie aplikacji jest to proces często wymagający dużo uwagi, doświadczenia oraz znajomości dobrych praktyk. Jako software developer, czy architekt polecam Ci sięgać jak najczęściej po gotowe rozwiązania dostawców chmurowych, które w znacznym stopniu ułatwią i automatyzują proces skalowania. Mam nadzieję, że znajomość tych 7 zagadnień, które mogłeś dziś poznać, pomoże Ci budować skalowalne i gotowe na rozwój aplikacje.
Autor:
Senior Java Developer w Infolet
Zastanawiasz się czy Twoje aplikacje są skalowalne



